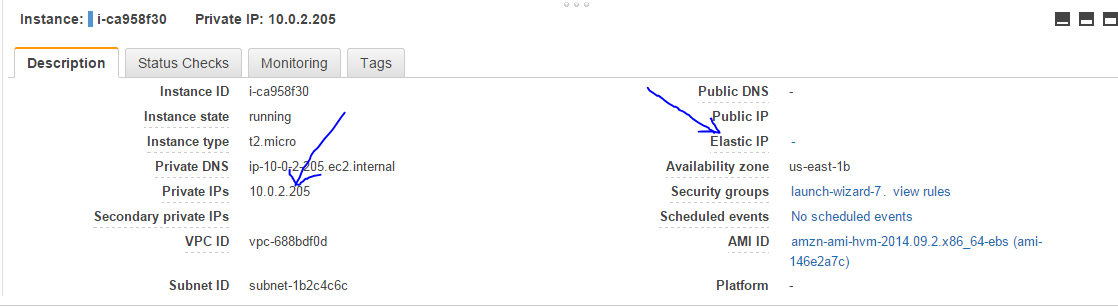
What is Version control It is a method used to keep a software system that can consist of many versions and configurations , well organized. Why Version control Usually through a period of the software development we might have various versions of software, code updates, hot fixes, bug fixes which all are revised over a period of time but we need to maintain the version and keep all the version intact so we might refrence them back over a period of time. Also in case of a problem with an updaded version of a software , we can always revert back to the older version easily using the version control software. All these things can easily be achieved using th version control software. There are large number of version control softwares 1. CVS: Kind of origin of source control 2. PVCS: Commercialized CVS 3. Subversion : inspired by CVS 4. Perforce : It is a commercial, proprietary revision control system developed by Perforce Software, Inc. 5. Microsoft visual sourcesafe:- M...